Googleアナリティクスの計測に「非人間」が増えてきた
- GAのbot除外が対象とするのは「既知のbot」のみ。自動化ブラウザー由来のアクセスが計測データに混入し、分析の判断材料を歪める可能性がある
- AIエージェントが普及すると「人間か機械か」という前提では整理しきれなくなる。どのような主体がどのような意図と方法でアクセスしたのかを問う視点が求められる
Googleアナリティクスの計測に人間以外のトラフィックが増えてきました。当社が管理するWebサイトのGoogleアナリティクスに計測されたトラフィックでは、約5〜10%が人間ではないようです。
自社サイトでは少し前から、自動化されたブラウザーアクセスの識別を試みています。直近1カ月間だとユーザーの約5%、PVの約3%が該当しています。管理している別のサイトでも計測を始め、そちらではユーザーの約10%、PVの約8%が識別されています。
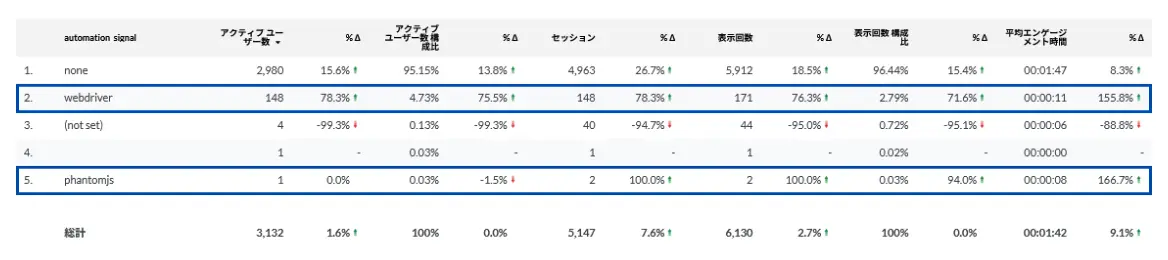
計測期間はまだ1~2カ月程度と短く、サイトの性質によっても変わるはずです。このデータを一般化するには慎重でありたいですが、「思っていたよりも多い」という印象です。今回はこの取り組みを通じて感じている話です。

識別しているのはヘッドレスブラウザー環境
識別しているのは、WebDriver、Selenium、PhantomJS、Nightmareといったヘッドレスブラウザー環境です。Googleタグマネージャーを使って自動化ブラウザーのアクセス時の特有のシグナルをJavaScriptで検知しています。
これは、Googleアナリティクスのbotの自動除外をすり抜けて計測されたbot全般を識別するものではありません。GAタグを実行する自動化ブラウザーの一部を識別しているものです。機械的なURL探索や巡回、確認処理、スクレイピングといったアクセスが含まれるとみています。
計測にあたっては、山田良太さんの記事を参考にしています。1
情報量が多いサイトや情報データベースとしての価値があるサイトほど、こうした自動化された巡回処理の対象になりやすいのかもしれません。先日、河野武さんの運営するお城検索サイト「攻城団」で類似する事象が起きている件も記事などで目にしていました。23
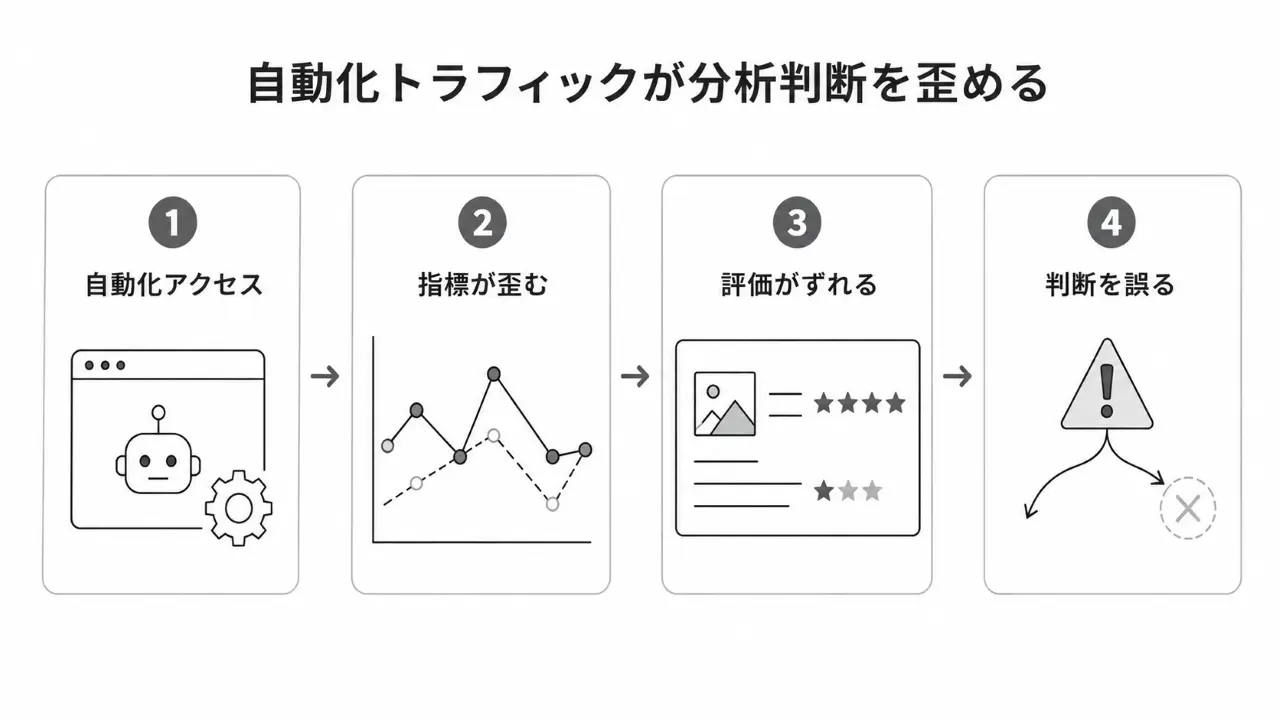
非人間トラフィックの混入は分析を狂わせる
Googleアナリティクスにはbotを自動除外する仕組みがあります。ただし、除外されるのはGoogleが把握している既知のbotに限られます。定義リストに含まれていない自動化アクセスは計測データに含まれます。
問題は、自動化トラフィックが通常のユーザーと異なる行動をとることです。
例えばエンゲージメント率は低く、セッション時間は極端に短い、ほとんどはdirect流入として計測され参照元URLも空になる。「/recruit/」「/saiyou/」「/inquiry/」といった「当社サイトには存在しないが一般的にその可能性のあるURLへのアクセス」が混ざることもあります。数日おきに定期的に一定量のトラフィックを発生する、というのも見られます。
このようなデータはページやトラフィックの分析を歪めます。「このページは閲覧はあるもののアクションが発生しておらず、改善が必要」といった誤った判断をしてしまうのです。
その結果、コンテンツ改善の優先順位を誤り、施策の評価もブレます。今後AIがデータを自動で分析するケースが増えるほど、計測データの質の影響は大きくなります。トラフィックが大きくないサイトでは、10%の混入でも判断への影響が大きくなるのも厄介です。
Web解析の価値は「計測したデータをどう解釈するか」にありますが、これは分析の前段階であるデータの質が問われており、真剣に向き合う必要があります。
「消す」ではなく「分けて見る」へ
取り組みを始める前は、ある程度の条件を特定した上で計測からの除外をうっすら検討していました。しかし現実的には困難です。
判定条件は増え続けます。User-Agentや端末情報は偽装できます。彼らはいっそう「人間らしい行動」に似せてきます。なにより判定を誤れば通常ユーザーのデータを失ってしまいます。
そのため、計測段階で除外するのではなく、識別して残す方がまずはよいだろうという判断になりました。通常のレポートや分析ではフィルターで外しつつ、自動化トラフィック自体は監視するというものです。
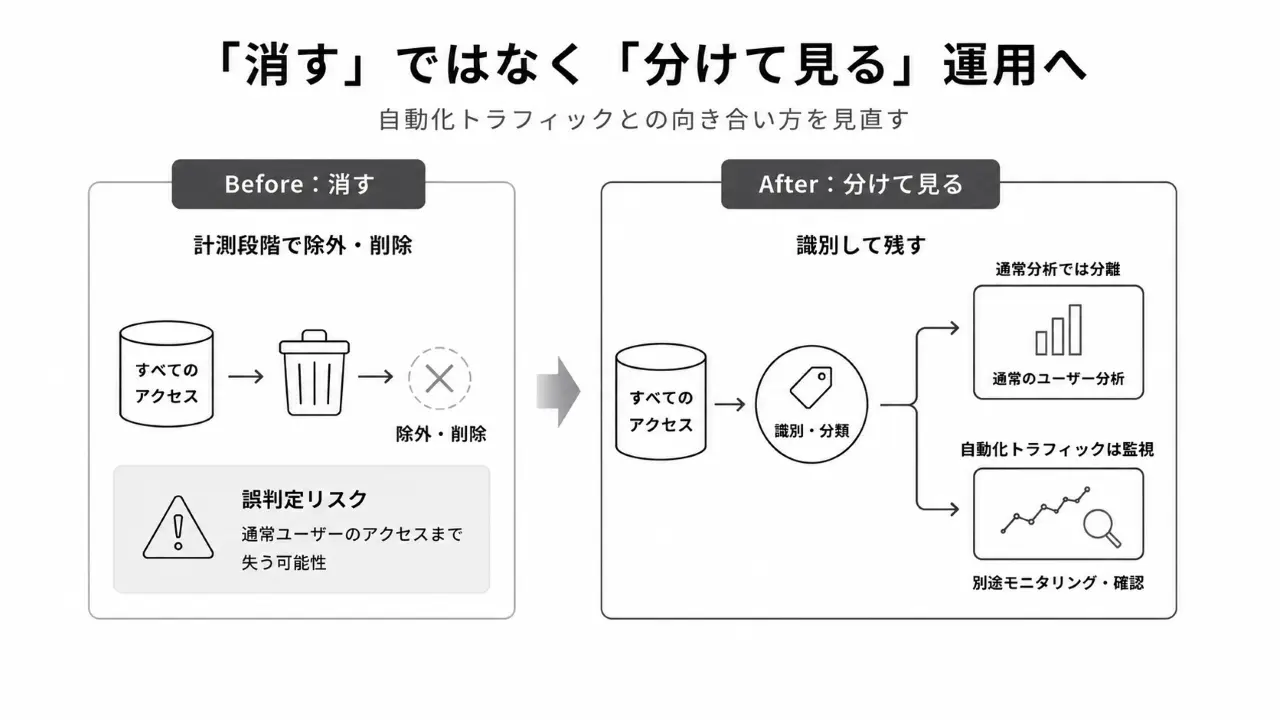
ただし、対応できるのは識別できた自動化トラフィックだけです。識別できないものは混在し続けます。そして今後はさらに難しい問題が出てきます。
AIエージェントのアクセスはGAで識別できるのか
これからのWebでは、AIエージェントがユーザーの代わりにWebサイトへアクセスするケースが増えてくるはずです。そのとき、そのアクセスを「botや自動化されたアクセスとして一括りに識別」してよいのでしょうか。あるいはそもそもできるのでしょうか。
Googleアナリティクスによる計測は、AIエージェントの種類によって異なりそうです。HTMLを取得するだけのfetcher型のアクセスは計測されにくいです。ヘッドレスブラウザー型であれば計測される可能性があり、自動化シグナルで識別できる場合もあります。一般のブラウザー上でAIが補助する形のアクセスであれば、通常ユーザーとおそらく同じように計測されます。
GPTBotやClaudeBotのように、User-Agentで自己申告するAIクローラーは基本的にはGoogleアナリティクスにほとんど計測されないfetcher型に近い存在です。Googleアナリティクスで計測されるようなAIエージェント型のアクセスは、現時点では識別は容易ではないと思われます。
「人間か機械か」という前提の限界
従来のWeb解析では暗黙の前提があったかもしれません。計測されるアクセスは「人間のものか」「botや機械によるものか」というものです。
しかしAIエージェントの普及が始まると、その境界は曖昧になります。ユーザーの指示に基づいてAIがWebサイトを調べに来るなら、そのアクセスは単純なノイズとは言い切れません。かといって通常ユーザーと見分けがつかないものを無理に除外もできません。むしろユーザーの指示に基づく代理行動であれば、AIエージェントであってもそれはユーザー行動の一種ではないか、とも思うのです。
識別できる自動化トラフィックは分けて見る。識別できないユーザー代理エージェントの行動は、当面は通常ユーザーと同等に扱うしかなさそう(むしろそうすべきかもしれない)。それがいまのところの考えです。
「人間か機械か」という前提は、考え直す必要がありそうです。「どのような主体が、どのような意図で、どのような方法でアクセスしたのか」という視点への移行となるのでしょうか。Web解析における「ユーザー行動」の定義が問い直されているフェーズかもしれません。

皆さんのサイトのGoogleアナリティクスでも、何%かの自動化されたアクセスが含まれているはずです。計測データをどう読むかについて、私たちはもう少し慎重である必要がありそうです。

関連記事
-
 「意味のある行動シグナル」を計測せよ
「意味のある行動シグナル」を計測せよ -
GA4のオーディエンス機能は「誰が重要か」を定義するフレームである
-
「空・雨・傘」とリンクする「データ→インフォメーション→インテリジェンス」の流れ
-
オンラインの行動データは必要とされ続けるだろう。例えばUXリサーチの側面などでね
-
Googleアナリティクスのチャネルの定義(UTMパラメータに規定の値を指定して自動判別させる)
-
「2022年6月までにGA4導入を終える」ではなく「1年間かけてGA4の基盤を整備し馴らしていく」ではないか
-
ダイレクトなトラフィックは、もうご指名流入ではなくダークトラフィックだ
-
コンテンツマーケティングの分析のための評価視点とGA4の計測整備







